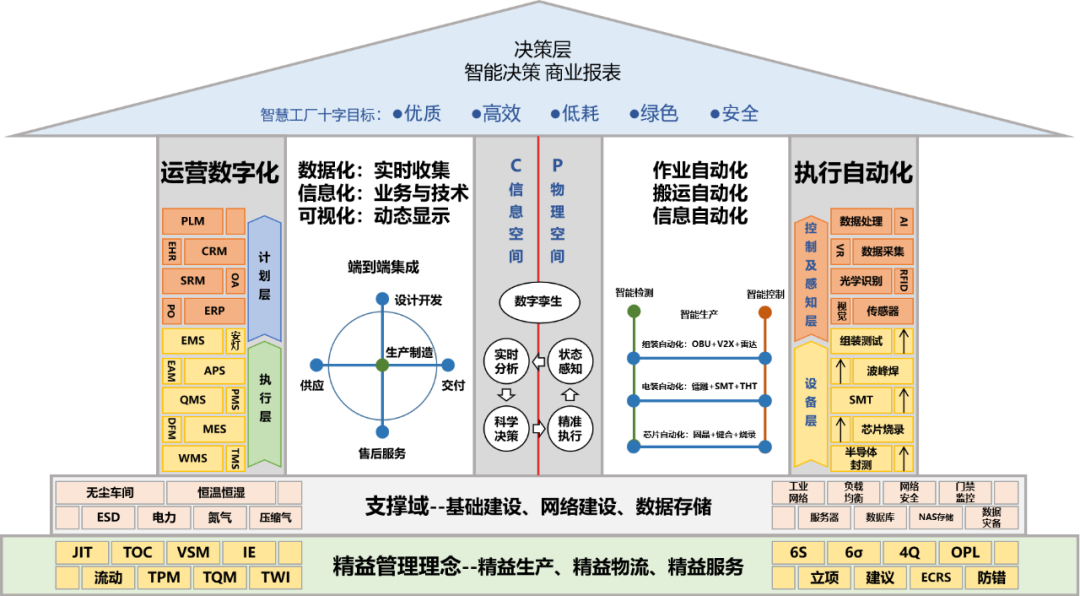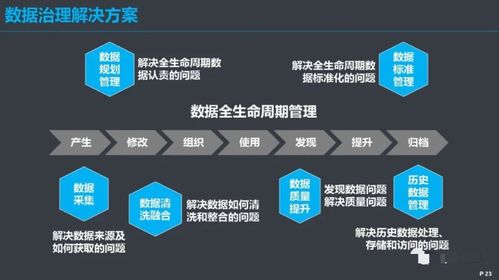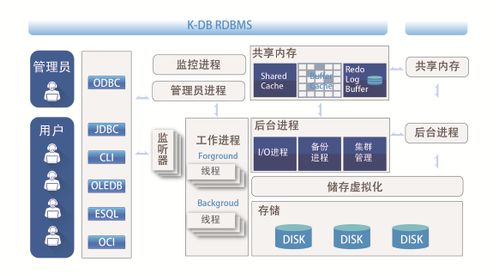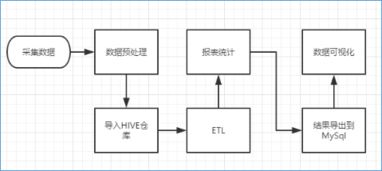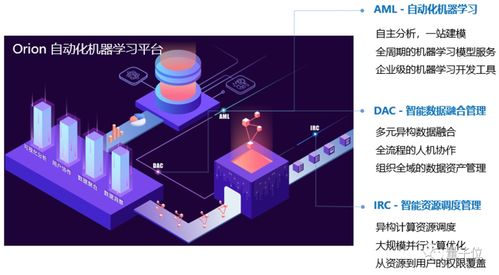
在人工智能技术浪潮席卷全球的今天,数据智能产品正以前所未有的深度和广度重塑各行各业。从精准的推荐系统、智能的自动驾驶,到高效的工业质检、前沿的药物研发,其核心驱动力无不源于海量、多样、高速流动的数据。在这光鲜的应用层之下,一个常被忽视却至关重要的基石正在默默支撑着整个智能体系的运转——那便是强大、可靠且智能化的存储支持服务。
一、数据洪流:AI时代对存储的根本挑战
传统的数据存储方案,在面对AI工作负载时,正遭遇着前所未有的压力。这主要体现在三个方面:
- 规模与成本的矛盾:AI模型的训练需要吞吐PB级乃至EB级的原始数据。存储如此海量的数据,同时控制不断攀升的硬件与运维成本,成为首要挑战。
- 性能与效率的瓶颈:训练过程需要存储系统能够以极高的吞吐量和低延迟,同时向成千上万个计算节点(GPU/TPU)供给数据。任何I/O瓶颈都会导致昂贵的算力资源闲置,极大拖慢模型迭代速度。
- 数据管理的复杂性:AI数据生命周期复杂,从采集、清洗、标注、版本管理,到训练、推理、归档,每个阶段对数据的访问模式、性能要求和存储成本都不同。如何实现数据的统一管理、无缝流动和智能分层,是提升整体效率的关键。
二、智能存储:从被动容器到主动赋能
为应对上述挑战,现代存储支持服务正在发生深刻演变,其核心是从简单的“数据存放处”进化为“数据赋能平台”。
1. 高性能并行文件系统与对象存储的融合
针对训练场景,高性能并行文件系统(如Lustre, GPFS, WekaFS)因其极高的聚合带宽和元数据性能,成为承载热数据、加速训练过程的首选。与此对象存储(如AWS S3, 开源Ceph)凭借其近乎无限的扩展性和成本优势,成为海量冷数据、模型checkpoint和数据集归档的“数据湖”底座。前沿的存储服务正通过智能缓存、透明分层等技术,将二者无缝融合,让数据在高速层与大容量层之间按需、自动流动。
2. 存算分离与云原生架构
存算分离架构已成为主流。计算资源(GPU集群)与存储资源独立弹性伸缩,避免了因存储容量或性能不足而整体扩容计算集群的浪费。结合Kubernetes等云原生技术,存储服务能够以容器化的方式动态提供,实现存储资源的敏捷部署、按需供给和精细化管理,完美适配AI训练任务快速启停、弹性伸缩的特点。
3. 数据感知与智能管理
最前沿的存储系统正在融入AI技术本身,实现“以AI管理AI数据”。例如:
- 智能数据预取与缓存:系统能够学习训练任务的数据访问模式,主动将所需数据预加载到高速缓存中,进一步消除I/O等待。
- 自动化数据生命周期管理:基于策略与数据热度分析,自动将不活跃的数据从高性能存储迁移到低成本存储,优化总体拥有成本(TCO)。
- 元数据增强与数据治理:提供强大的元数据管理能力,支持数据溯源、版本控制、血缘分析,并与MLOps平台深度集成,确保数据质量、合规性与可重复性。
三、未来展望:存储即智能基础设施
存储支持服务在AI生态中的角色将愈发核心和主动。我们或将看到:
- 存储与计算的更深层协同:通过计算存储(Computational Storage)或近数据处理(Near-Data Processing)技术,将部分数据过滤、预处理任务卸载到存储层内部执行,极大减少不必要的数据移动,提升整体能效。
- 面向AI工作负载的专用硬件与协议:随着DPU/IPU的兴起,存储的智能卸载和加速能力将更强。NVMe-oF等高性能网络存储协议将进一步普及,实现数据中心级的高性能共享存储池。
- 跨云、边、端的统一数据平面:为支持联邦学习、边缘推理等场景,存储服务需要提供一个全局统一的数据访问、同步和管理视图,确保数据与模型在中心、边缘和终端之间安全、高效地协同。
###
在数据智能产品与技术飞速发展的前沿,存储支持服务已不再是后台的默默支撑者,而是直接决定AI研发效率、创新速度和落地成本的关键赋能层。只有构建起能够理解数据、感知业务、动态优化的智能存储基础设施,我们才能真正释放海量数据的潜能,让AI的浪潮持续澎湃向前。对任何致力于在AI领域取得突破的组织而言,投资和优化其“存储智慧”,与投资算力和算法同等重要。