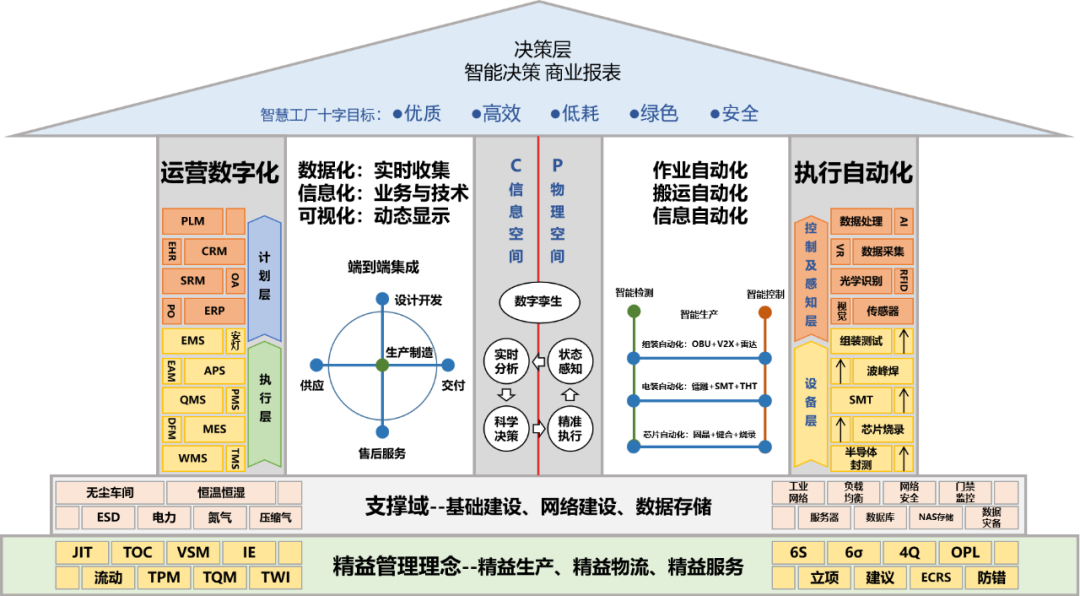
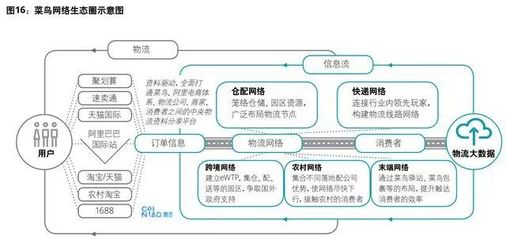
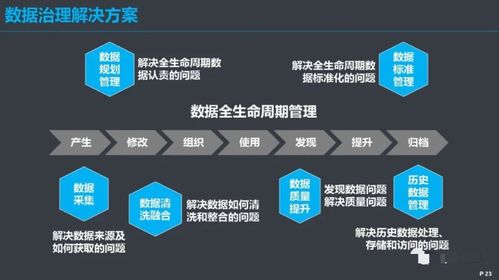
在当今信息爆炸的时代,“大数据”已从一个技术术语演变为驱动社会进步与商业创新的核心引擎。它不仅仅指代海量的数据集合,更代表着一整套现代计算概念和先进数据处理范式的融合。理解其背后的计算逻辑与处理流程,是把握数字未来脉搏的关键。
一、 现代大数据计算的核心概念
大数据的现代计算体系建立在几个相互关联的核心概念之上,它们共同构成了处理超大规模、多类型、快流速数据的理论基础。
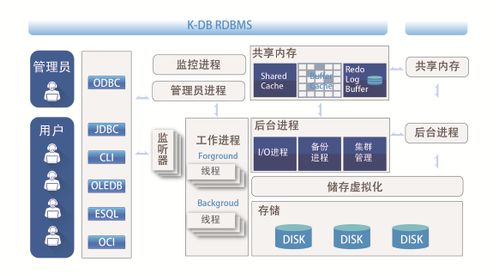
- 分布式计算:这是大数据计算的基石。传统单机系统无法应对TB乃至PB级的数据处理需求。分布式计算(如Hadoop的MapReduce、Spark)将庞大的计算任务分解成无数个小任务,分配到成百上千台普通商用服务器组成的集群中并行处理,最后汇果。这种方式实现了横向扩展(Scale-out),通过增加廉价机器来提升整体计算能力,具有高性价比和高容错性。
- 流式计算:针对数据产生速度极快的场景(如物联网传感器、社交媒体推送、金融交易),批处理模式显得滞后。流式计算(如Apache Flink、Apache Storm、Spark Streaming)专注于对无界数据流进行实时或近实时的连续处理,实现毫秒级到秒级的响应,支撑实时监控、风险预警和即时推荐等应用。
- 内存计算:传统数据处理严重依赖磁盘I/O,成为性能瓶颈。以Apache Spark为代表的内存计算框架,将中间计算结果和热数据存储在集群各节点的内存中,极大减少了磁盘访问次数,使迭代计算和交互式查询的速度提升数十倍乃至百倍,实现了“快数据”处理。
- 图计算:对于社交网络、知识图谱、路径规划等场景,数据间关系至关重要。图计算(如Apache Giraph、GraphX)以“顶点”和“边”为基本单元,专门优化关联分析与复杂网络计算,能高效解决诸如社区发现、影响力传播、最短路径等传统方法难以处理的问题。
二、 大数据处理的全生命周期
数据处理是使原始数据转化为价值洞见的实践过程,贯穿数据从产生到消亡的整个生命周期,主要包括以下关键环节:
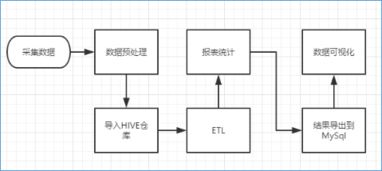
- 数据采集与集成:这是数据处理的源头。需要从异构数据源(数据库、日志文件、传感器、APP、公开数据集等)中,通过ETL(提取、转换、加载)或ELT流程,将多源、多格式(结构化、半结构化、非结构化)的数据高效、可靠地汇聚到统一的存储平台(如数据湖)。现代技术如Apache Kafka、Flume等实现了高吞吐、低延迟的实时数据采集与传输。
- 数据存储与管理:面对海量数据,存储系统需具备高扩展性、高可靠性和成本效益。这催生了两种主流范式:
- 分布式文件系统:如HDFS,提供跨机器的海量文件存储基础。
- NoSQL数据库:如键值存储(Redis)、列族存储(HBase)、文档数据库(MongoDB)、图数据库(Neo4j),它们牺牲了传统关系数据库的强一致性或复杂事务支持,换取了在特定数据模型下的高扩展性与高性能。
- NewSQL数据库与数据湖仓:融合了SQL优势与分布式扩展能力(如Google Spanner),以及将数据湖的灵活性与数据仓库的管理性结合(如Delta Lake),成为新趋势。
- 数据处理与分析:这是价值提炼的核心阶段,可分为多个层次:
- 批处理:对静态数据集进行周期性、大规模深度分析,如历史报表生成、用户行为挖掘。
- 流处理:如前所述,进行实时计算与响应。
- 交互式查询:通过如Presto、Impala等引擎,支持分析师对海量数据进行亚秒级到秒级的即席查询。
- 机器学习与高级分析:利用Spark MLlib、TensorFlow on Hadoop等框架,直接在数据平台上进行模型训练与预测,实现数据智能。
- 数据可视化与应用:将分析结果以图表、仪表盘、报告等直观形式呈现(如Tableau、Superset),赋能决策。数据洞见被集成到业务应用、推荐系统、风险模型等具体场景中,形成闭环,驱动业务增长与优化。
三、 融合与未来趋势
当前,大数据计算与处理正朝着云原生、智能化、一体化的方向演进。云服务提供了弹性的计算与存储资源,简化了大数据平台的运维。人工智能,特别是机器学习,与大数据流程深度嵌套,实现了从“描述分析”到“预测与决策”的跃迁。批流一体(如Apache Flink)、湖仓一体等融合架构正在消除数据处理中的壁垒,构建更统一、高效的数据栈。
总而言之,大数据的现代计算概念与数据处理是一个动态发展的庞大体系。它以分布式系统为筋骨,以多样化的计算模式为脉络,以全生命周期的数据处理流程为血液,共同将原始数据转化为驱动社会与商业前行的智慧与动能。掌握这些核心,方能在大数据的浪潮中行稳致远。